by Kevin Breen
This article is the fourth in a biweekly series examining AI and its implications for publishers and authors.
More than those in most industries, literarians like to spend their time and money in ways that align with their values. We love to support independent bookstores and presses whenever possible. We run prizes and open submission windows for marginalized and underrepresented authors. We publish stories and literature because of their artistic value, often irrespective of their financial upside.
It follows that small presses would be deeply concerned about the ethical implications of genAI and its usage. How is data sourced? Are there safeguards? Is copyright being violated? Do all genAI outputs constitute plagiarism?
Especially with such a fast-moving, polarizing technology, it can be hard to sincerely and honestly consider genAI in the context of our work. That’s why it’s important to look at the theoretical ethics of genAI, how that stacks up against its real-world usage, and if or when genAI can be used in ways that align with small presses’ values.
Framing the conversation
As we noted in the first article in this series, the term “AI” has been applied to a wide swath of technologies over several decades. Some might argue that a word processor’s spell-check tool is a manifestation of AI or that auto-completing email software crosses a similar threshold. For the purposes of this article, we are confining the debate to genAI outputs that would otherwise be completed by humans. This narrower definition excludes aid from auto-complete tools, for example, while focusing our attention on novel outputs from large language models (LLMs).
GenAI in a vacuum
Is there any version of genAI that is ethical? If we look at the technology’s theoretical framework, an answer begins to emerge. To recap: a large language model like ChatGPT is trained on immense datasets that it subsequently “learns from” and then uses to produce “novel” outputs. This is distinct from previous technologies, which could only regurgitate a finite number of pre-cached answers.
There is a world in which the steps used to build genAI tools are ethically achieved:
- Training data is sourced from the public domain or it is licensed via agreements with the rights holders, like publishers or authors themselves.
- The tokenization process, and the parameters applied to the model, are made transparent to end users.
- Like other written materials, the outputs of LLMs are held to the same citation and fair-use standards.
In short, there are theoretical ways to build and maintain ethical LLMs. But what happens when these ethical considerations butt up against financial, industrial, and competitive demands?
The ethics of sourcing data
Extensive reporting has illuminated the data arms race currently underway in the genAI sphere. As of now, there’s not enough publicly available, reliable data to make LLMs entirely fluent in human storytelling. Companies have tried, and are trying, many strategies to resolve this issue: transcribing a million hours of YouTube videos, trying to acquire the mega-publisher Simon & Schuster, feeding AI-generated content back into their models as training data.
When a shortage like this occurs, and there are massive incentives to build the best and biggest LLMs as fast as possible, ethical shortcuts get taken. As Alex Reisner explained in an Atlantic article, “A culture of piracy has existed since the early days of the internet, and in a sense, AI developers are doing something that’s come to seem natural. It is uncomfortably apt that today’s flagship technology is powered by mass theft.” Reisner’s September 2023 reporting revealed that 191,000 books “were used without permission to train generative-AI systems by Meta, Bloomberg, and others.” (The dataset, Books3, which is linked to in the Atlantic article can be searched to see if your work was improperly used in AI training.)
Other companies have also cut ethical corners. The New York Times reported that Google broadened its terms of service “to be able to tap publicly available Google Docs, restaurant reviews on Google Maps and other online material for more of its A.I. products.” Companies like these have sunk tremendous costs into getting their genAI tools partway to completion. As the quantity of unused data continues to shrink, they seem exponentially more motivated to find any available input data.
There’s also the fear that material and prompts shared with LLM chatbots can then be dredged for future use. For example, if you share your entire novel with ChatGPT and ask it to write your book’s back-cover text, does it now have perpetual access to your manuscript? OpenAI’s documentation says “no,” though of course, users are right to be skeptical. Google’s Gemini offers a slightly, shall we say wishy-washy, answer. When I asked if it can be trained on the questions I pose to it, Gemini said it does not “retain or ‘remember’ specific conversations” but that whatever I write to it it “can inform my future responses in a general sense.” Here, it seems like Gemini is splitting hairs, differentiating between formal training-data inputs and generalized “learning.”
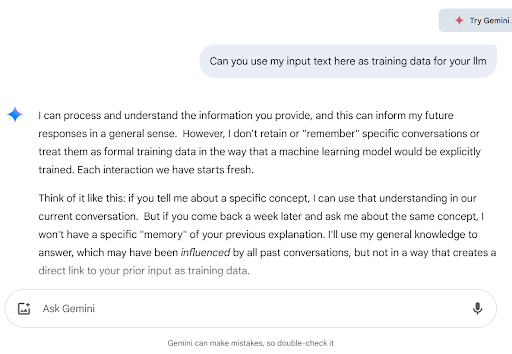
Gemini’s response to my question about using inputs as training data, sassy italicization and all!
The murkiness of LLM operations
Just as companies are increasingly motivated to source data from wherever they can, there is also a competitive advantage to covertly building large language models. ChatGPT, for example, relies on a proprietary algorithm. So, while the ethical argument against AI often boils down to its intellectual theft, the models themselves are only valuable insofar as their methods for ingesting, parsing, and reproducing text remain private.
Fair use versus plagiarism
The legal merits of LLMs hinge on the idea of fair use. In a lawsuit against OpenAI led by The New York Times, the publishers represented have argued that ChatGPT “has included millions of copyrighted works” in its training. This, they say, amounts to “copyright infringement on a massive scale.”
Meanwhile, OpenAI’s lawyers say the technology is “protected by ‘fair use’ rules.” As NPR Bobby Allyn writes, “In order to clear the fair use test, the work in question has to have transformed the copyrighted work into something new, and the new work cannot compete with the original in the same marketplace, among other factors.” In other words, OpenAI’s lawyers believe ChatGPT has ingested, and transformed, the copyrighted work into something new. This idea aligns with anthropomorphizing language companies use to describe their LLMs: they “ingest” and “create” rather than “receive inputs” and “reassemble text snippets” into “a patchwork output response.”
Sometime in the near future, US courts will decide whether LLMs are covered by fair use doctrine. Meanwhile, individual consumers will need to decide for themselves whether or not genAI chatbots are considered plagiarism.
Purdue OWL’s overview of plagiarism describes it as “using someone else’s ideas or words without giving them proper credit.” Given all we know about LLMs–their closely guarded proprietary technology, the way they source data, the lack of attribution provided in their outputs–one thing is clear. Plagiarism and LLMs, as currently constructed, go hand in hand.
Environmental considerations
It’s hard to ignore how resource-intensive genAI can be. Like cryptocurrencies and blockchain technology, genAI requires a huge amount of computing power. That demand diverts energy, water, and other finite resources away from preexisting uses and toward this new industry. In May, Bloomberg reported that an average 100-megawatt data center “uses more power than 75,000 homes combined” and “consumes about 2 million liters of water per day,” equivalent to the water consumption of 6,500 households.
Professor Daniel Carney says the average ChatGPT query uses 10 times as much energy as a traditional search-engine result. Meanwhile, a study found that generating 1,000 AI images produces about as much CO2 as driving 4.1 million miles in an average gas-powered car.
At scale and over time, the use of genAI would have huge impacts on our energy footprint. The World Economic Forum says that by 2030, “global power demand from data centres–primarily driven by AI–could increase by 18-20% annually.” All other detractions aside, such rampant consumption would seem like a nonstarter for publishers. Already, small presses are sensitive to positive and negative environmental impacts like FSC-certified paper, print-on-demand, shipping, pulped returns, and more. It’s hard for many literarians to imagine adopting an ancillary service and dramatically increasing their carbon footprint.
Looking ahead
Practically speaking, it’s getting harder and harder to avoid 100% of genAI. Every Google search begins with a genAI summary. LLMs are becoming more fluent in the ways humans write and shape stories. You probably get prompted to try out new integrated genAI features every time you open Microsoft Word, Photoshop, or the broader Adobe Creative Suite. For those publishers who are committed to opposing genAI in their work lives, it will be important to be specific and adaptable when it comes to anti-AI policies. Would you accept a submission from a novelist who authored their manuscript entirely on their own, but who used genAI to hammer out a query letter? Would you hire a freelancer who took a genAI image from Adobe Stock and used it as a crude template for their human-drafted illustration?
These kinds of gray-area questions emphasize the need for clear policies from publishers, transparent communication with writers, and alignment between the presses, authors, and industry professionals who come together to produce the books we love.
Kevin Breen lives in Olympia, Washington, where he works as an editor. He is the founder of Madrona Books, a small press committed to place-based narratives from the Pacific Northwest and beyond.
